



RAG
RAG介绍
检索增强生成 (RAG) 是一种使用来自私有或专有数据源的信息来辅助文本生成的技术。它将检索模型(设计用于搜索大型数据集或知识库)和生成模型(例如大型语言模型 (LLM),此类模型会使用检索到的信息生成可供阅读的文本回复)结合在一起。
通过从更多数据源添加背景信息,以及通过训练来补充 LLM 的原始知识库,检索增强生成能够提高搜索体验的相关性。这能够改善大型语言模型的输出,但又无需重新训练模型。额外信息源的范围很广,从训练 LLM 时并未用到的互联网上的新信息,到专有商业背景信息,或者属于企业的机密内部文档,都会包含在内。
RAG 对于诸如回答问题和内容生成等任务,具有极大价值,因为它能支持生成式 AI 系统使用外部信息源生成更准确且更符合语境的回答。它会实施搜索检索方法(通常是语义搜索或混合搜索)来回应用户的意图并提供更相关的结果。
下图是一个RAG链路的两个阶段,包括Indexing pipeline阶段和RAG的阶段。
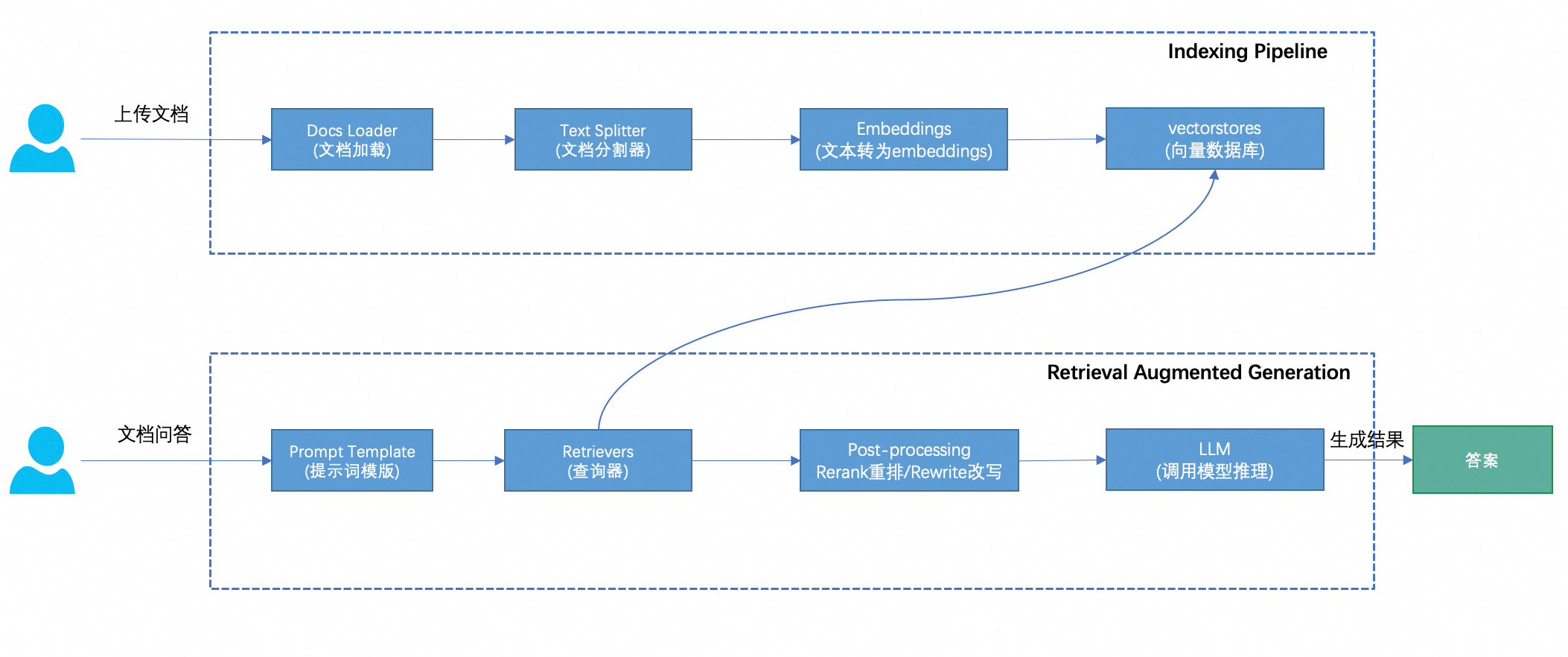
从上图可以看到, indexing pipeline的阶段主要是将结构化或者非结构化的数据或文档进行加载和解析、chunk切分、文本向量化并保存到向量数据库。 RAG的阶段主要包括将prompt文本内容转为向量、从向量数据库检索内容、对检索后的文档chunk进行重排和prompt重写、最后调用大模型进行结果的生成。
RAG调用
知识库内容导入
下边是将pdf文档导入到知识库的代码
DashScopeApi dashscopeApi = ...;
// 1. 解析文档和chunk切分String filePath = "新能源产业有哪些-36氪.pdf";DashScopeDocumentCloudReader reader = new DashScopeDocumentCloudReader(filePath, dashscopeApi, null);List<Document> documentList = reader.get();DashScopeDocumentTransformer transformer = new DashScopeDocumentTransformer(dashscopeApi);List<Document> transformerList = transformer.apply(documentList);System.out.println(transformerList.size());
// 2. 文档向量化DashScopeEmbeddingModel embeddingModel = new DashScopeEmbeddingModel(dashscopeApi);Document document = new Document("你好阿里云");float[] vectorList = embeddingModel.embed(document);
// 3. 导入文档内容到向量存储DashScopeCloudStore cloudStore = new DashScopeCloudStore(dashscopeApi, new DashScopeStoreOptions("bailian-knowledge"));cloudStore.add(Arrays.asList(document));
// 4. 删除文档cloudStore.delete(Arrays.asList(document.getId()));知识问答
下边代码将根据之前创建的知识库,进行知识问答的代码:
DocumentRetriever retriever = new DashScopeDocumentRetriever(dashscopeApi, DashScopeDocumentRetrieverOptions.builder() .withIndexName("bailian-knowledge") .build());
ChatClient chatClient = ChatClient.builder(dashscopeChatModel) .defaultAdvisors(new DocumentRetrievalAdvisor(retriever)) .build();
ChatResponse response = chatClient .prompt() .user("如何快速开始百炼?") .call() .chatResponse();String content = response.getResult().getOutput().getContent();Assertions.assertNotNull(content);
logger.info("content: {}", content);如果需要返回检索召回后,模型采纳和引用的文档内容, 可以通过以下代码实现:
DocumentRetriever retriever = new DashScopeDocumentRetriever(dashscopeApi, DashScopeDocumentRetrieverOptions.builder() .withIndexName("spring-ai知识库") .build());
ChatClient chatClient = ChatClient.builder(dashscopeChatModel) .defaultAdvisors(new DashScopeDocumentRetrievalAdvisor(retriever, true)) .build();
ChatResponse response = chatClient .prompt() .user("如何快速开始百炼?") .call() .chatResponse();
String content = response.getResult().getOutput().getContent();Assertions.assertNotNull(content);logger.info("content: {}", content);
//获取引用的内容List<Document> documents = (List<Document>) response.getMetadata().get(DashScopeDocumentRetrievalAdvisor.RETRIEVED_DOCUMENTS);Assertions.assertNotNull(documents);
for (Document document : documents) { logger.info("referenced doc name: {}, title: {}, score: {}", document.getMetadata().get("doc_name"), document.getMetadata().get("title"), document.getMetadata().get("_score")); }