



对话模型(Chat Model)
对话模型(Chat Model)接收一系列消息(Message)作为输入,与模型 LLM 服务进行交互,并接收返回的聊天消息(Chat Message)作为输出。相比于普通的程序输入,模型的输入与输出消息(Message)不止支持纯字符文本,还支持包括语音、图片、视频等作为输入输出。同时,在 Spring AI Alibaba 中,消息中还支持包含不同的角色,帮助底层模型区分来自模型、用户和系统指令等的不同消息。
Spring AI Alibaba 复用了 Spring AI 抽象的 Model API,并与通义系列大模型服务进行适配(如通义千问、通义万相等),目前支持纯文本聊天、文生图、文生语音、语音转文本等。以下是框架定义的几个核心 API:
- ChatModel,文本聊天交互模型,支持纯文本格式作为输入,并将模型的输出以格式化文本形式返回。
- ImageModel,接收用户文本输入,并将模型生成的图片作为输出返回。
- AudioModel,接收用户文本输入,并将模型合成的语音作为输出返回。
Spring AI Alibaba 支持以上 Model 抽象与通义系列模型的适配,并通过 spring-ai-alibaba-starter AutoConfiguration 自动初始化了默认实例,因此我们可以在应用程序中直接注入 ChatModel、ImageModel 等 bean,当然在需要的时候也可以自定义 Model 实例。
Chat Model
ChatModel API 让应用开发者可以非常方便的与 AI 模型进行文本交互,它抽象了应用与模型交互的过程,包括使用 Prompt 作为输入,使用 ChatResponse 作为输出等。ChatModel 的工作原理是接收 Prompt 或部分对话作为输入,将输入发送给后端大模型,模型根据其训练数据和对自然语言的理解生成对话响应,应用程序可以将响应呈现给用户或用于进一步处理。
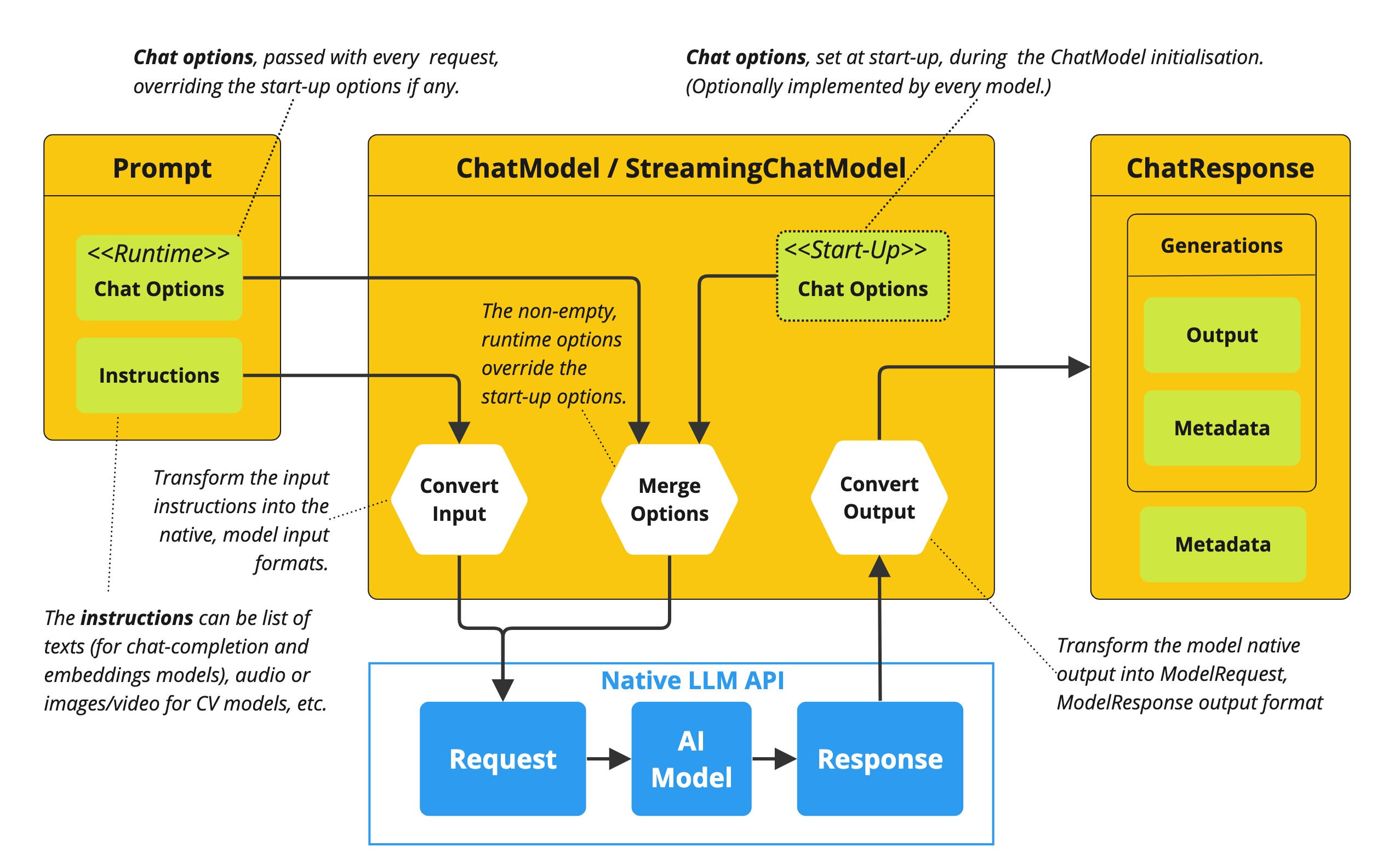
使用示例
开发完整的 ChatModel 示例应用,您需要添加 spring-ai-alibaba-starter 依赖,请参考快速开始中的项目配置说明了解详情,您还可以访问 chatmodel-example 查看本示例完整源码。
以下是 ChatModel 基本使用示例,它可以接收 String 字符串作为输入:
@RestControllerpublic class ChatModelController { private final ChatModel chatModel;
public ChatModelController(ChatModel chatModel) { this.chatModel = chatModel; }
@RequestMapping("/chat") public String chat(String input) { ChatResponse response = chatModel.call(new Prompt(input)); return response.getResult().getOutput().getContent(); }}使用 Prompt 作为输入:
Streaming 示例:
通过 ChatOptions 在每次调用中调整模型参数:
Image Model
ImageModel API 抽象了应用程序通过模型调用实现“文生图”的交互过程,即应用程序接收文本,调用模型生成图片。ImageModel 的入参为包装类型 ImagePrompt,输出类型为 ImageResponse。
使用示例
spring-ai-alibaba-starter AutoConfiguration 默认初始化了 ImageModel 实例,我们可以选择直接注入并使用默认实例。
@RestControllerpublic class ImageModelController { private final ImageModel imageModel;
ImageModelController(ImageModel imageModel) { this.imageModel = imageModel; }
@RequestMapping("/image") public String image(String input) { ImageOptions options = ImageOptionsBuilder.builder() .withModel("dall-e-3") .build();
ImagePrompt imagePrompt = new ImagePrompt(input, options); ImageResponse response = imageModel.call(imagePrompt); String imageUrl = response.getResult().getOutput().getUrl();
return "redirect:" + imageUrl; }}通过 ImageOptions 在每次调用中调整模型参数:
Audio Model
当前,Spring AI Alibaba 支持以下两种通义语音模型的适配,分别是:
- 文本生成语音 SpeechModel,对应于 OpenAI 的 Text-To-Speech (TTS) API
- 录音文件生成文字 DashScopeAudioTranscriptionModel,对应于 OpenAI 的 Transcription API