



Overview
Service registration and discovery
The biggest difference between microservices and traditional monolithic application architectures is the emphasis on the splitting of software modules. Under the monolithic architecture, multiple functional modules of an application system are organized and deployed and run in the same application process. Therefore, the response to a request can be completed directly through method calls between modules. However, in a microservice system, an application system needs to be split according to its functional characteristics and then deployed separately at a certain granularity, in order to achieve high cohesion within the module, low coupling between modules, and high reliability of the entire microservice system. Scalability:
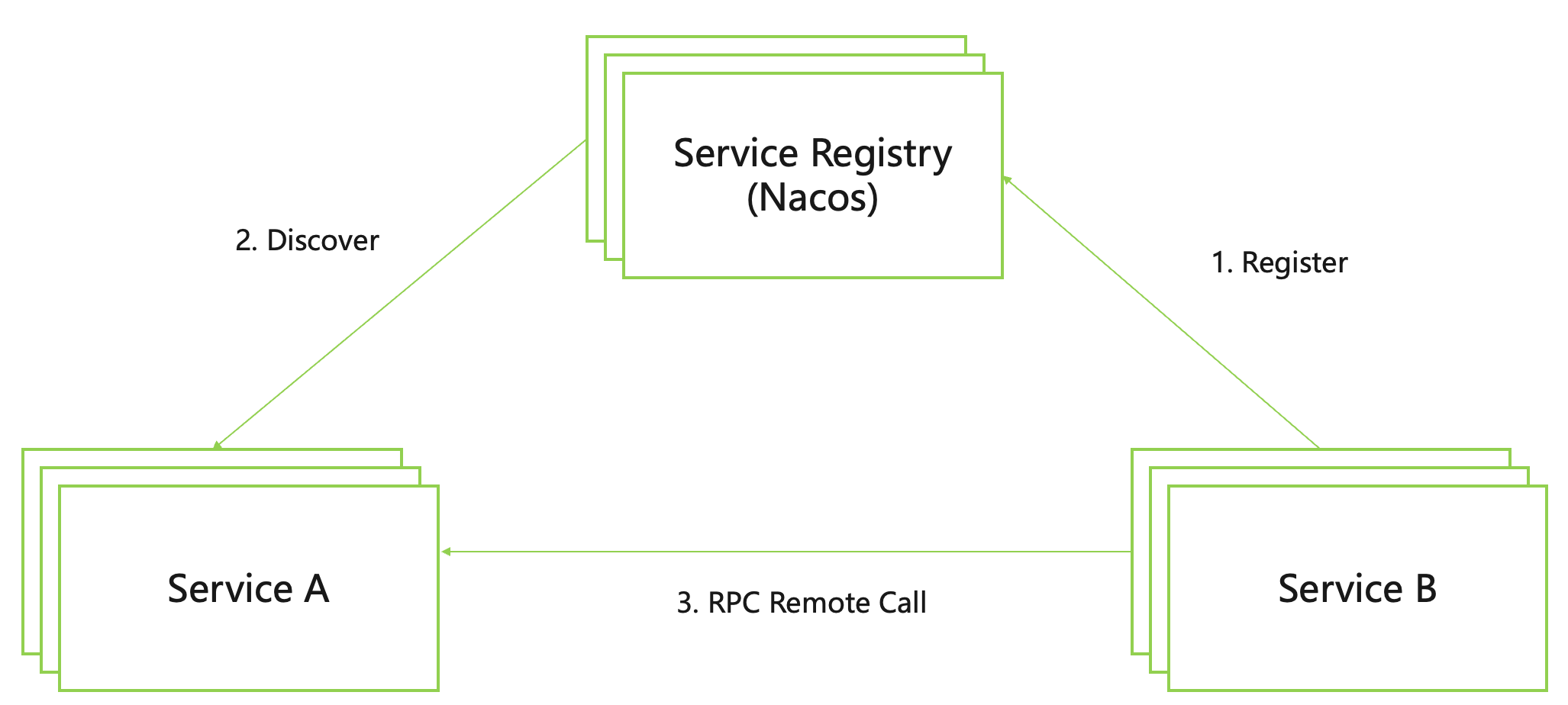
It turns out that the request processing that can be completed in one application at a time will lead to cross-process and cross-host service calls. How to make these services discover each other and provide unified external service call capabilities like a single application is the microservice framework level One of the core issues that needs to be addressed. In the Spring Cloud ecosystem, the following service registration and discovery model is adopted to realize mutual discovery and invocation between microservices.
 )
)
As shown in the figure above, a component called registry is introduced into the microservice system as a coordinator. The most simplified process is that all microservice applications will send information including service name, host IP address and port number to the registration center during the startup process, and then the upstream microservice will process the request according to the service Name to the registry to find all the instance IP addresses and port numbers of the corresponding service to call the service. The whole process is shown by the dotted line in the figure. In this way, the scattered microservice systems can provide request processing capabilities to the outside world as a whole.
Configuration management
Before formally introducing the content of distributed configuration, let’s briefly introduce the concept of configuration. The configuration in the software system refers to various settings and parameters required during the running of the software, including system configuration, application configuration, and user configuration. System configuration includes the setting of basic environmental parameters such as operating system, hardware, and network; application configuration includes the setting of various parameters and options of the application program, such as database connection strings, log levels, etc.; user configuration refers to user-defined Various options and parameters, such as shortcut keys, interface layout, language, etc. Configuration in the software system is an important supplement to the software source code, through which the execution behavior of the software system can be easily adjusted to make the software system more flexible. In addition to monolithic applications, in distributed systems, configuration information is widely used, and different functions can be realized through configuration. These configuration information include database connection information, log level, business configuration and so on. In traditional development methods, these configuration information are usually hard-coded into the code of the application, packaged and deployed together with the program code. However, this method has many disadvantages, such as configuration information is not easy to maintain, as long as the configuration is modified, it has to be rebuilt and deployed.
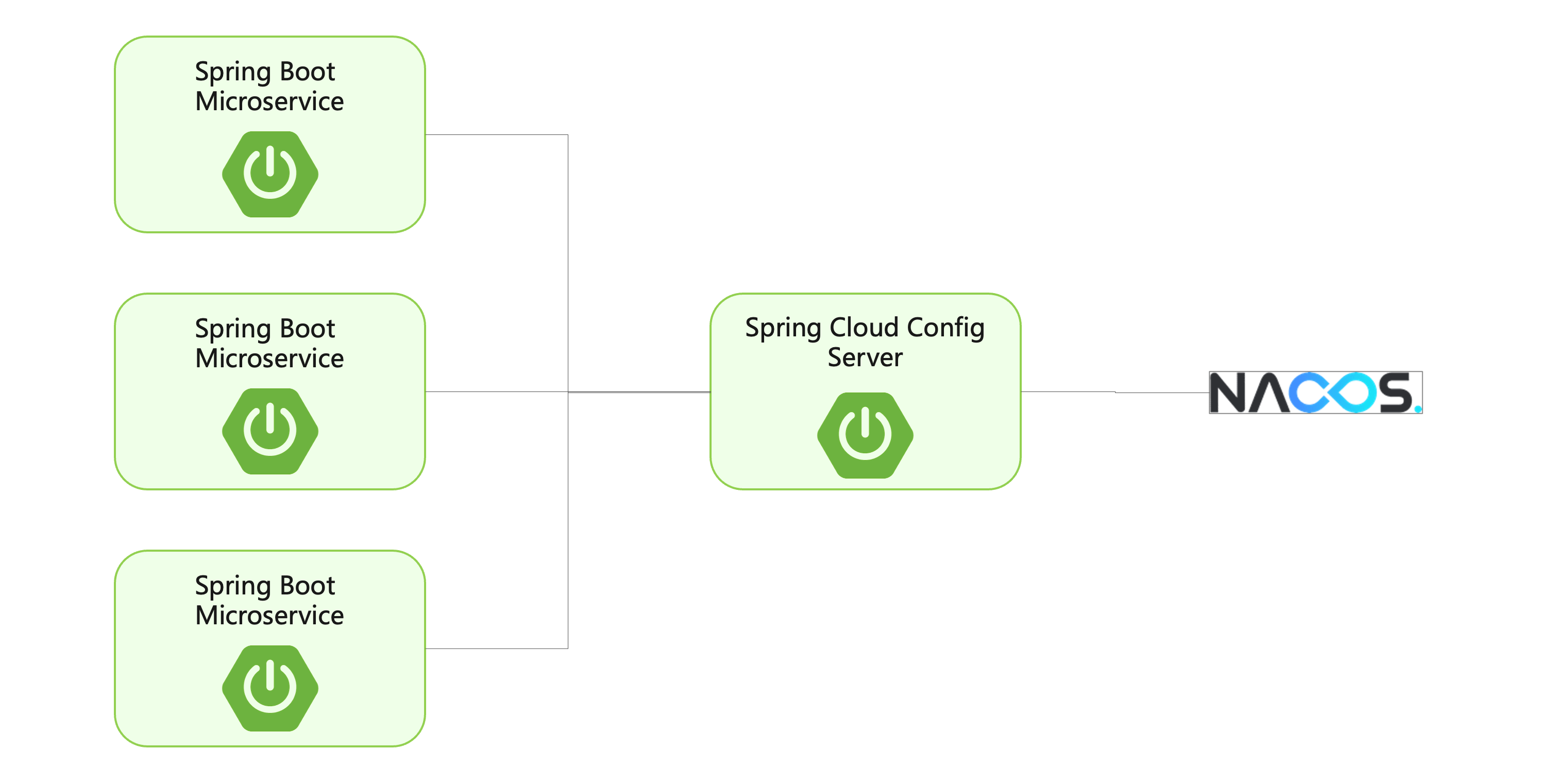
The software architecture using the distributed configuration center is shown in the figure above, which can help solve the following problems in distributed scenarios:
- Manage application configurations: When there are a large number of applications to manage, manually maintaining configuration files can become very difficult. The distributed configuration center provides a solution for centrally managing and distributing configuration information.
- Environment isolation: In different environments such as development, testing, and production, the configuration information of the application is often not used. Using the distributed configuration center, you can easily manage and distribute configuration information in different environments.
- Improve program security: Storing configuration information in the code base or application files can lead to security risks because the information can be accidentally leaked or exploited by malicious attackers. Using distributed configuration, configuration information can be encrypted and protected, and access rights can be controlled.
- Dynamically update configuration: When the application is running, it may be necessary to dynamically update the configuration information so that the application can respond to changes in a timely manner. Using a distributed configuration center, configuration information can be dynamically updated at runtime without restarting the application.
Nacos overview
Nacos /nɑ:k əʊs/ is the acronym for Dynamic Naming and Configuration Service, a dynamic service discovery, configuration management and service management that is easier to build cloud-native applications platform.
Nacos is dedicated to helping you discover, configure and manage microservices. Nacos provides a set of easy-to-use feature sets to help you quickly realize dynamic service discovery, service configuration, service metadata, and traffic management.
Nacos helps you build, deliver and manage microservice platforms more agilely and easily. Nacos is a service infrastructure for building a “service”-centric modern application architecture (such as microservice paradigm, cloud native paradigm).

