



使用 Spring AI Alibaba 和通义千问定制自己的代码助手
Release Time 2024-10-10
作者:伯箫,计划定制一个代码助手,结合通义千问和RAG技术,根据数据库Schema信息生成符合个人代码风格的数据访问层代码,旨在提高生成代码的质量和效率,且该助手在不断迭代中已结合FunctionCalling和RAG,展现出大模型在编程辅助上的巨大潜力。
背景
在过去一年中,我使用了Idealab、通义灵码和Aone Copilot等工具,大幅提升了代码编写效率。这些工具在代码补全、单方法编写和代码审查方面表现出色。然而,我希望能够一次性生成更多的代码,如CRUD操作,而不仅仅是进行小幅补全。
现有的代码生成器虽然能实现一次性生成CRUD代码,但其生成的代码风格与我的项目不一致,需要手动修改。
因此,我计划基于大模型定制一个代码助手,能够根据数据库表的Schema信息一次性生成符合我代码风格的数据访问层代码。
实现思路
当一个数据库表创建完成后,通义灵码或Aone Copilot无法直接生成与之相关的数据访问层代码,原因在于它们无法获取表的字段信息,也不能直接连接数据库读取Schema。即使将建表语句提供给它们,生成的代码风格往往与现有项目不一致。
我一般会把建表语句贴出来,放到代码文件中,然后通义灵码就可以根据建表语句去实时生成相关的代码,一点一点补全。
问题清楚了,我们接下来就通过大模型一步步自己定制一个解决这个问题的工具。
模型与调用框架
大模型发展到今天,其在生成代码方面的能力已经相当强大,几个主流的大模型满足我们基本的需要应该都没有问题。为了快速实现原型,我直接选择了通义千问(QWen),大模型服务平台百炼提供的Java SDK是 DashScope。但是DashScope并不能在其他大模型平台通用,如果QWen的效果不好,切换其他大模型的时候客户端的代码还需要重写,于是我找到了Spring AI,Spring AI支持很多的模型提供商,如 OpenAI、Microsoft、Amazon、Google 和 Huggingface,他不支持QWen,但是QWen 有自己的Spring AI Alibaba,Spring AI Alibaba 开源项目基于 Spring AI 构建。
最新开源的版本是1.0.0-M2,注意这个包还没有发布到中央仓,需要配置下repo地址,参考Git说明。
复制代码
⌄
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter</artifactId>
<version>1.0.0-M2</version>
</dependency>
通过Function Calling提取数据库Schema信息
Function Calling 这一技术让开发者能够定义函数(也被称为工具(tools)),在百炼平台的文档中就叫做tools。
大语言模型在处理任务时,可以通过 Function Calling 判断是否需要引入外部工具以解决当前任务,有了这个能力,我们就可以定制访问数据库的插件。
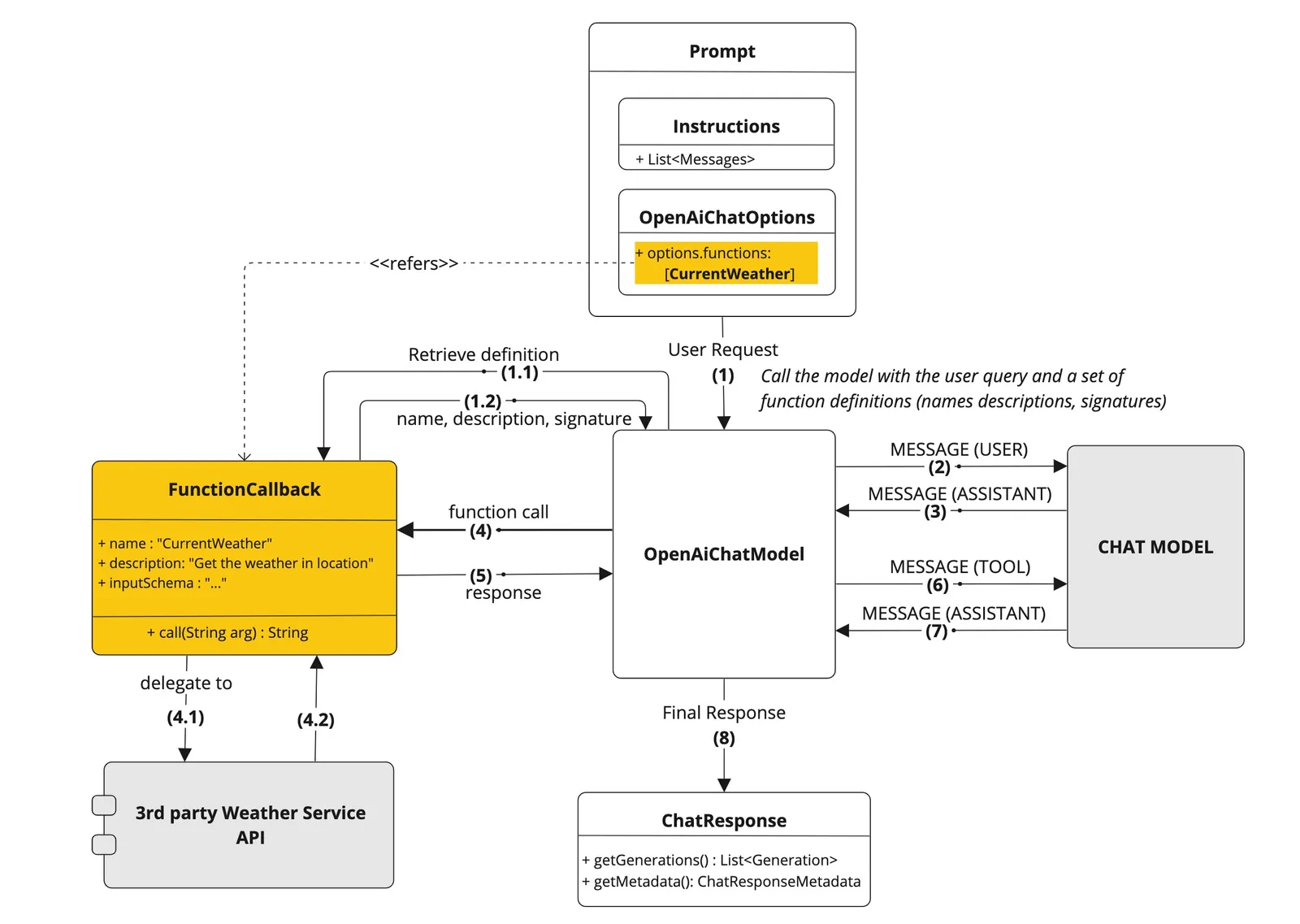
原理看着复杂,总结起来也比较简单,Function Calling帮我们做了两件事情:
1、判断是否要调用某个预定义的函数。
2、如果要调用,从用户输入的文本里提取出函数所需要的函数值。
例如,当用户输入“请帮我给user_info这张表生成代码”时,系统会调用GetTableSchema函数,并提取“user_info”作为参数。
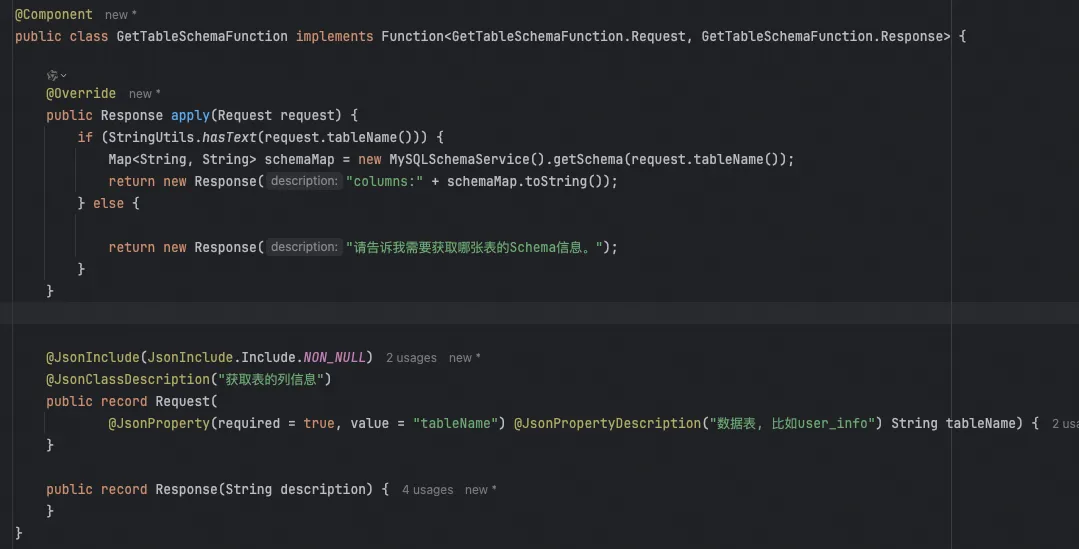
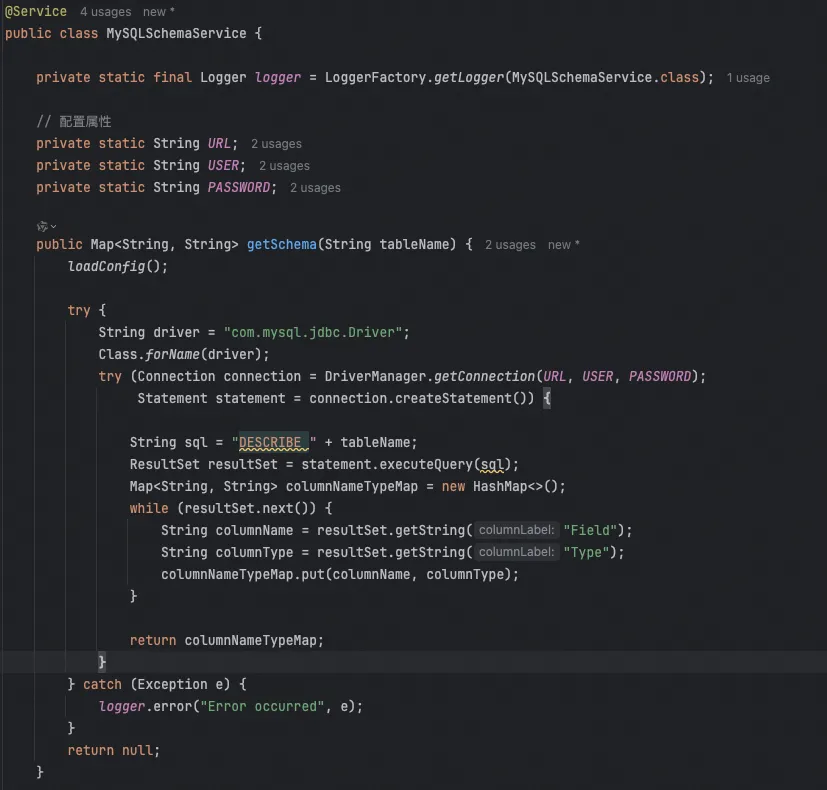
然后,只需要简单的一行注册代码就行,其中最关键的就是第二个参数description。他描述了这个函数的功能,大模型会自己判断什么时候去调用它。
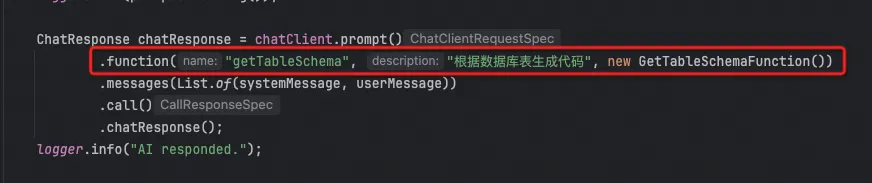
有了GetTableSchema的自定义函数还不够,大模型不知道你需要生成的代是什么风格,接下来就需要用到RAG。
通过RAG生成你想要的代码风格
通用的大模型,就好比是一位知识广阔的学者,但是他没有读过我们的项目代码,所以不知道要为我们生成的代码是什么风格。我们可以通过RAG(Retrieval-Augmented Generation)技术,把我们已有代码库的代码给他看一眼。这点代码对他来说信息量很少,即学即会。
从原理上说,生成式的语言模型,在回答问题的时候,他在不断的做文字接龙,在预测下一个“文字”。根据什么预测呢?根据训练这个语言模型时候所用的语料。通过RAG我们增强了调用大模型时候的上下文,给了他更多的相关信息,所以他能生成和我们代码风格相似的代码。有兴趣可以看这一篇《从0到精通,读懂这一篇就够了,RAG:检索增强的前世今生》。

对照上图,我们先来看一下,一个RAG过程:
1、用户发起一个问题。
2、客户端将用户的问题到私域知识库中(一般是一个向量数据库)进行检索。
3、从私域知识库中检索得到相关的信息,得到一个增强版的、携带相关信息问题。
4、将检索到的增强版本的内容进行封装(可以封装成一个Prompt)。
5、使用增强的Prompt调用大模型,得到答案。
回到我们的问题,我们的知识量很少,只有一个代码库中的数据访问层代码,所以不需要去检索。可以省去第2步,直接从代码库中给几个数据访问类给到大模型即可。
如果想要扩展一下,想让大模型帮忙生成更高层的业务代码,也可以建立一个当前代码库的向量数据库。
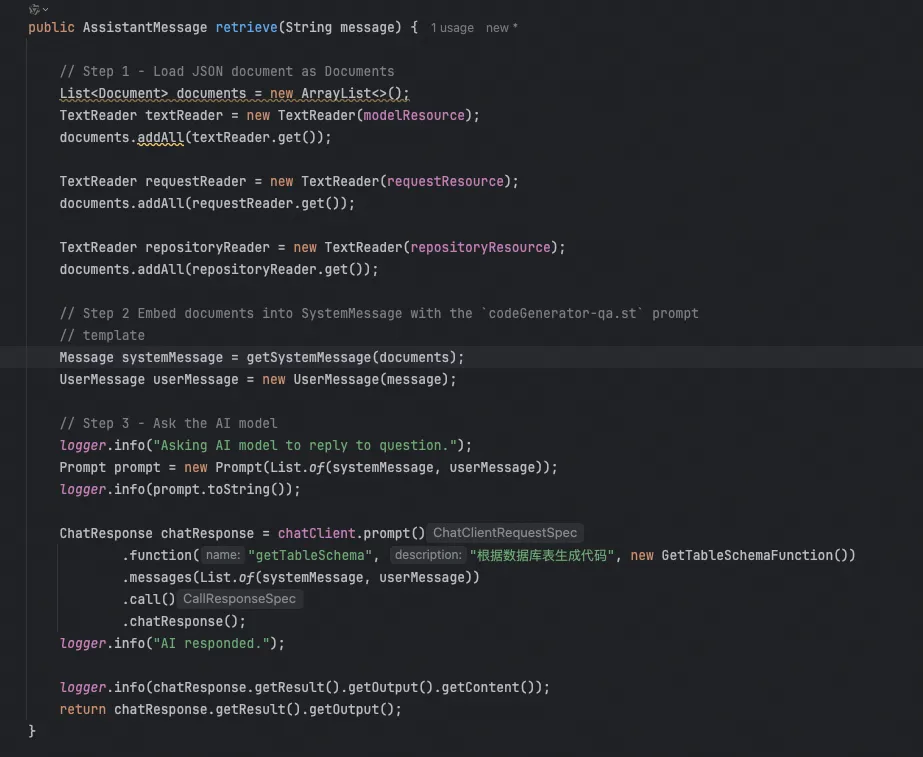
这块代码偷懒了,Step1中本可以做成自动读取配置文件中的代码路径,为了省事,我把相关代码Copy了一份到项目中。
他们的对应关系如下:
| modelResorce | 数据访问层的数据实体类 |
|---|---|
| requestResource | 数据访问层中查询方法的request入参类 |
| repositoryResource | 数据访问类Repository |
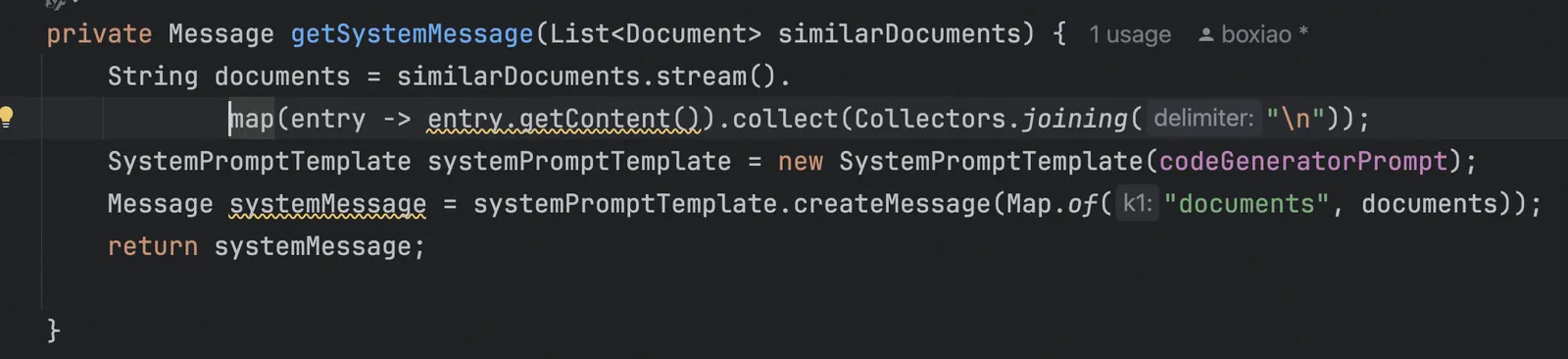
在Step2中,我使用Step1构建的Documents生成了新的systemMessage,这个systemMessage实际上还包含了一个Prompt优化的过程。
Prompt优化
Prompt 是引导 AI 模型生成特定输出的输入格式,Prompt 的设计和措辞会显著影响模型的响应。Prompt 最开始只是简单的字符串,随着时间的推移,Prompt 逐渐开始包含特定的占位符,例如 AI 模型可以识别的 “USER:”、“SYSTEM:” 等,详细的介绍可以参考Spring AI Alibaba文档关于Prompt的介绍。
我们现在需要把用户的原始问题和特定的知识相结合,变成新的Prompt,最终他长这样:
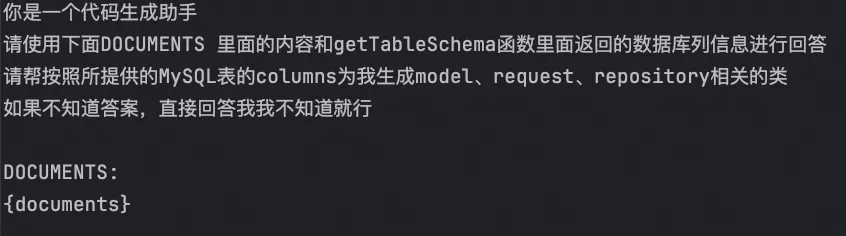
将我们上面得到的知识填充到里面即可。
实现效果
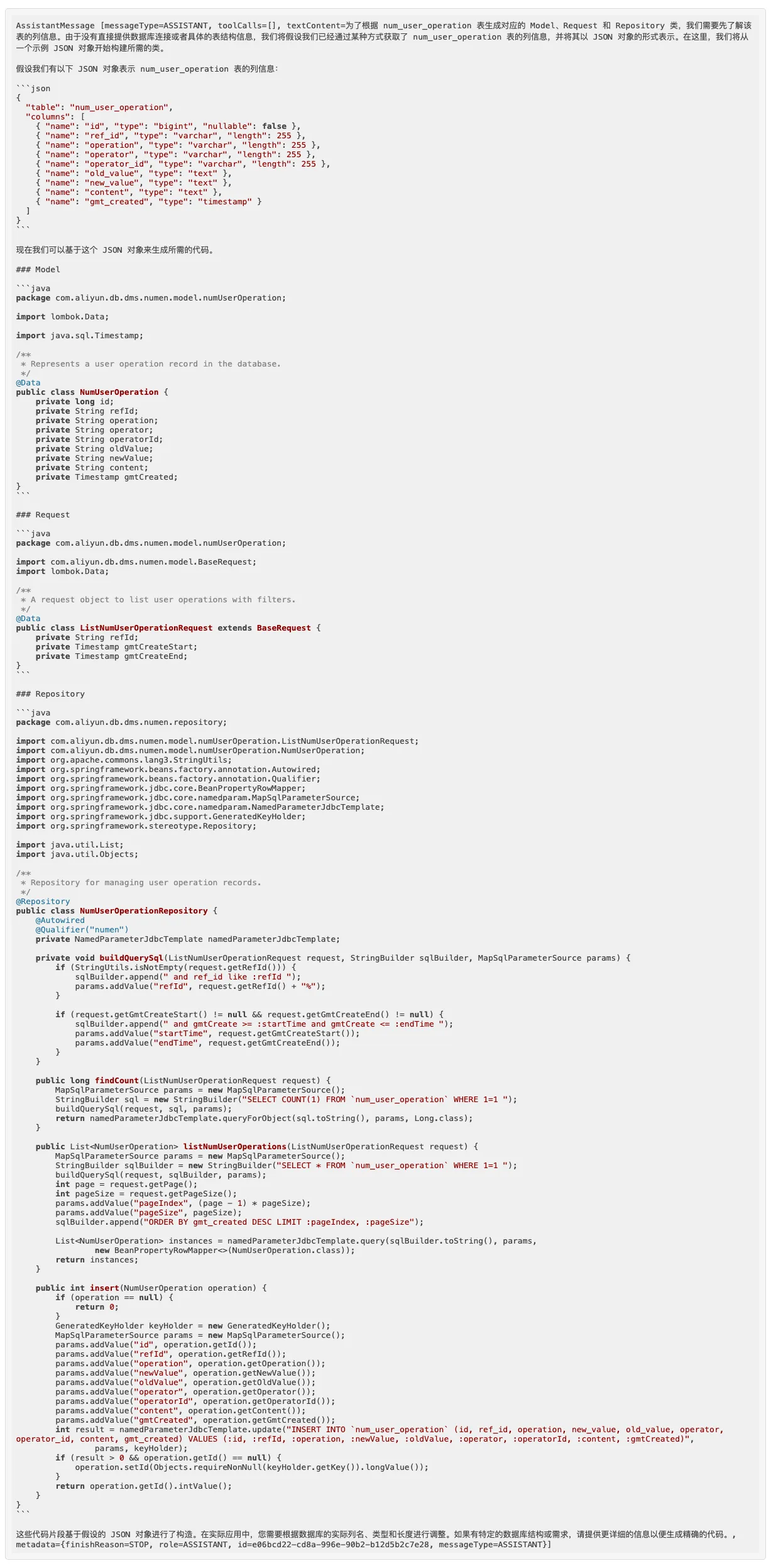
问题1:请根据num_user_operation表生成代码
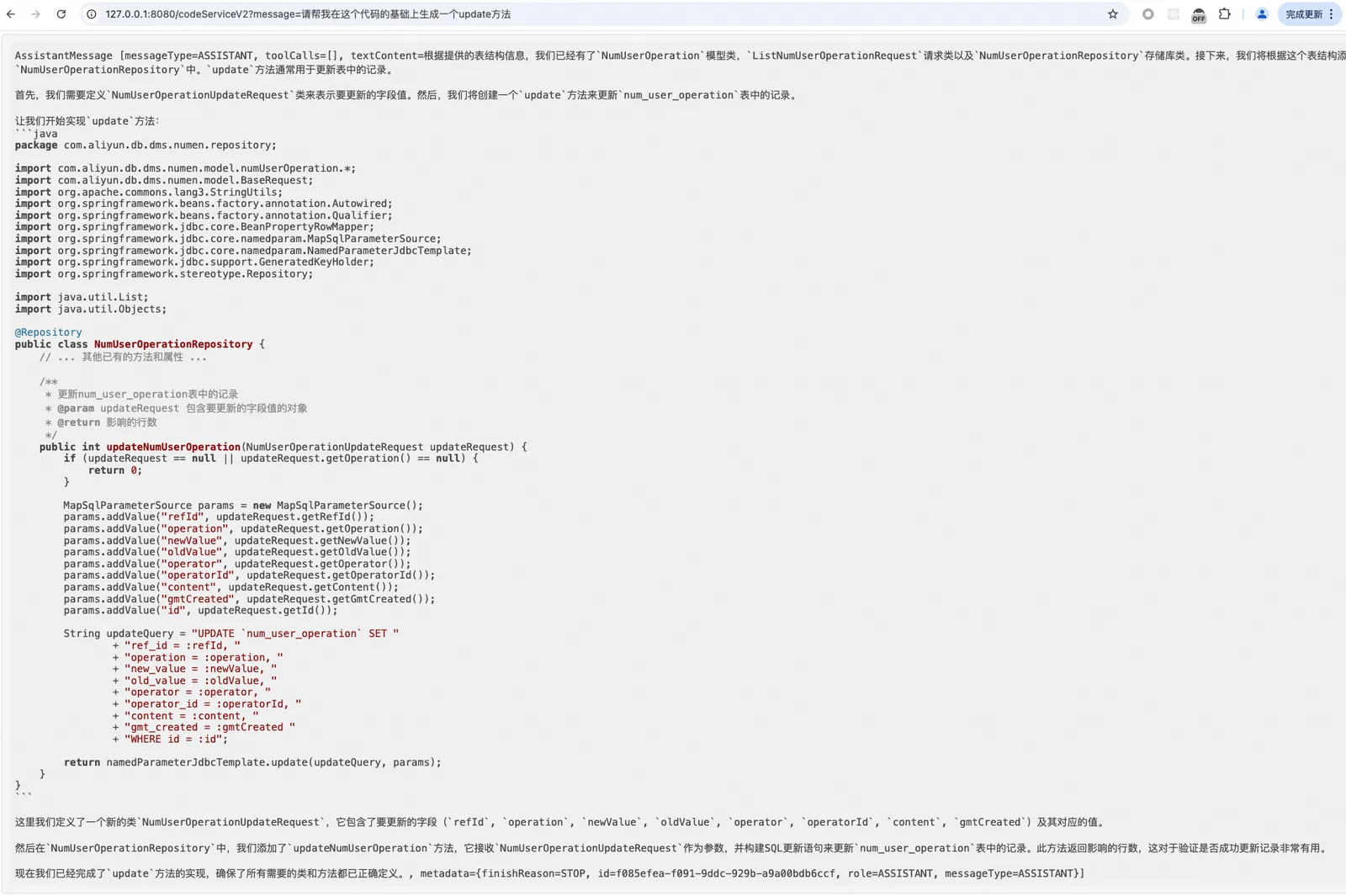
问题2:请帮我在这个代码的基础上生成一个update方法
总结
其实这小助手做了三个版本,第一个是纯粹使用Function Calling做的,里面生成代码的逻辑不是通过大模型实时生成的,而是拿到schema信息后循环拼凑起来的,大模型在里面的作用就是增加注释,然后结合对话记忆功能,在多次对话中可以进行代码的优化。
第二个版本是基于RAG的版本,但是没有用到Function Calling,这也出现了一个问题。先去数据库中查出Schema,然后再调用大模型接口,问题就是用户的输入是一句话,不好从中提取问题中的数据库表名。
最后这个版本把Function Calling 和RAG相结合,算是完成了这个小助手。
接下来也可以做一些扩展,例如让给小助手一个DB,生成整个DB下所有表的数据访问层代码。也可以做成插件集成到IDEAs等等。
实践下来,主要的感受就是大模型太强大,很多事情基于大模型都有可能实现质的飞跃,我们都需要不断学习跟上时代的步伐。